KGE-BERT--Inspire BERT with Knowledge Graph Embedding for Question Answering
The ability to understand the text and answer questions based on that is a fundamental but challenging task for machines in Natural Language Processing field. Instead of selecting the answers from a list of given choices, the system should locate the answer in the paragraph, which requires a deep understanding towards the given text. It has many applications such as Web search and dialogue systems. In this project, we aim to design and implement a new NLP model that given a paragraph and a question, it can first determine whether the question is answerable and then output the answer from the paragraph. Solving this problem is expected to help lay the foundation for comprehension ability of machines.
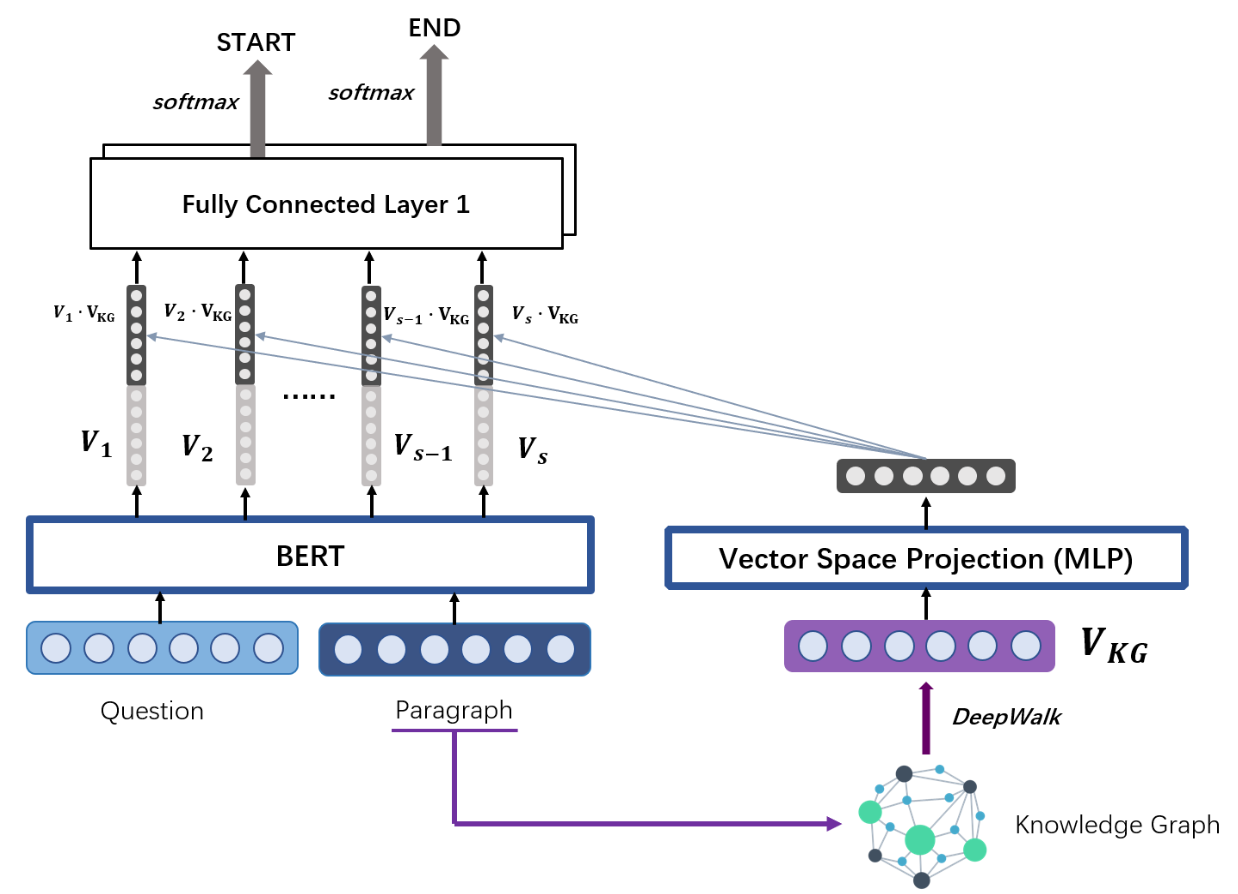
The final design for our model architecture is shown above. For the BERT Embeddding Layer, we feed into one paragraph context together with one question as normal. The preprocessing part of the input context and question has been mentioned in the data preprocessing part above.
For the knowledge graph embedding part, we firstly extract the entity pairs from the paragraph context through dependency parsing using spaCy to construct the knowledge graph. To get the knowledge graph embedding which shows the relationship between entity nodes, we apply DeepWalk. It uses local information obtained from random walks to learn latent representations for nodes in the graph by treating walks as the equivalent of sentences. We set the dimension of the knowledge graph embedding as 300. For each paragraph, we only select five entities with their knowledge graph embeddings. The selection of those five entities are based on their relevance with the question. We use gensim:’glove-wiki-gigaword-300’ to get the word embedding for each entity. As for the question, we average the embedding vector of each word in the question to get the sentence embedding. Then, the entities are ranked by their cosine similarity with that sentence embedding of the question. Getting the five entities, we concatenate their knowledge graph embeddings into one vector of size 5 × 300. However, we can not just directly inject this vector since it’s actually the space representation of entities and thus, its vector space is heterogeneous with the vector space of the BERT model output. Instead, we feed the knowledge graph embedding into vector space projection module, the fully connected layer before injecting it to the BERT output.
To help the system predict the answer from the paragraph, we want to inject the information of entities relationship which is relevant with the question in the paragraph context. Thus, we make dot product between the knowledge graph embedding vector and each output vector from BERT Layer. Then we concatenated the result with each original output vector.
Finally, we feed the output vectors above into a fully connected layer to get two scores for each output. One for start position and another represents the end position. Softmax function will be applied respectively to determine the answer in the paragraph. After choosing the position with largest probability as the start of the answer, we choose the position after that with largest probability as the end of the answer. If both start and end position are zero, it indicates that there is no answer to the question.
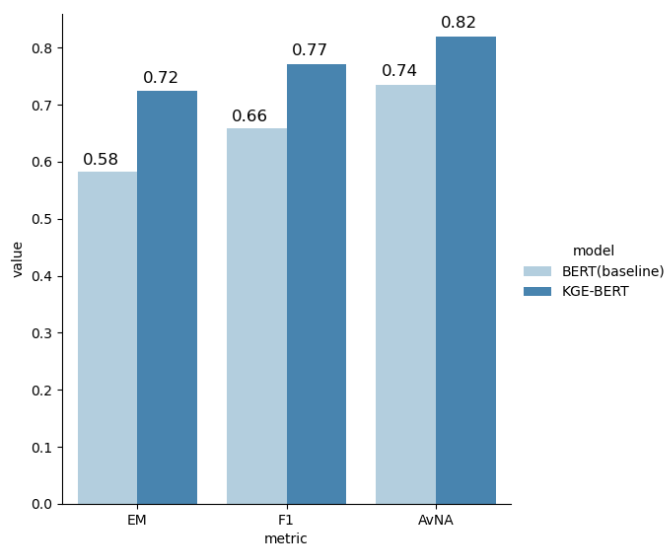
Baseline Model Performance
- F1: 0.58
- EM: 0.66
- AvNA: 0.74
KGE-BERT Model Performance
- F1: 0.77
- EM: 0.72
- AvNA: 0.82
Yingzhuo Yu
Undergraduate Student